Abstrakt
At finde nye peptid biomarkører for mavekræft i humane sera, som kan implementeres i en klinisk praktisk forudsigelse metode til overvågning af mavekræft. Vi studerede serum peptidindhold fra to forskellige biorepositories. Vi først ansat en C8-omvendt fase væskekromatografi tilgang for prøve oprensning, efterfulgt af massespektrometri-analyse. Disse blev påført på serumprøver fra kræft-fri kontroller og maven kræftpatienter på forskellige kliniske stadier. Vi derefter skabte en bioinformatik analyse pipeline og identificerede peptid signatur diskriminere mave adenocarcinom patienter fra kræft-fri kontrol. Matrix Assisted Laser Desorption /ionisering-Time of Flight (MALDI-TOF) resultater fra 103 prøver afsløret 9 signatur peptider; med forudsigelse nøjagtighed på 89% i træningssættet og 88% i valideringen sæt. Tre af de diskriminere peptider opdaget var fragmenter af Apolipoproteiner C-I og C-III (apoC-I og C-III); vi kvantificeret yderligere deres serumniveauer samt CA19-9 og CRP, beskæftiger kvantitative kommerciel-kliniske analyser i 142 prøver. kvantitative ApoC-I og apoC-III resultater korrelerede med MS resultater. Vi derefter ansat apoB-100-normaliseret apoC-I og apoC-III, CA19-9 og CRP niveauer for at generere regler for mavekræft forudsigelse. Til træning, brugte vi sera fra en repository, og til validering, vi brugte sera fra den anden repository. Prediction nøjagtighed på 88,4% og 74,4% blev opnået i uddannelses- og validering sæt hhv. Serum niveauer af apoC-I og apoC-III kombineres med andre kliniske parametre kan tjene som grundlag for formuleringen af en diagnostisk score for patienter mavekræft
Henvisning:. Cohen M, Yossef R, Erez T, Kugel A, Welt M, Karpasas MM, et al. (2011) Serum Apolipoproteiner C-I og C-III reduceres i mavekræft Patienter: Resultater fra MALDI-Based peptidindhold og Immuno-Based Clinical Analyser. PLoS ONE 6 (1): e14540. doi: 10,1371 /journal.pone.0014540
Redaktør: Hana Algül, Technische Universität München, Tyskland
Modtaget: Juli 1, 2010; Accepteret: November 22, 2010; Udgivet: 18 Jan 2011
Copyright: © 2011 Cohen et al. Dette er en åben adgang artiklen distribueres under betingelserne i Creative Commons Attribution License, som tillader ubegrænset brug, distribution og reproduktion i ethvert medie, forudsat den oprindelige forfatter og kilde krediteres
Finansiering:. Funding var fra det Europæiske Fællesskab (FP6 GLYFDIS 037.661). RNTech SAS France er angivet som bidragyder på grund af det faktum, at JT og HB er /var ansatte i dette selskab; bidrag JT og HB er defineret som endelige godkendelse af den version der skal offentliggøres, og de ikke var involveret i bidrag til udformning og design, eller erhvervelse af data eller analyse og fortolkning af data eller udarbejdelsen af manuskriptet. De finansieringskilder havde ingen rolle i studie design, indsamling og analyse af data, beslutning om at offentliggøre, eller forberedelse af manuskriptet
Konkurrerende interesser:. Det faktum, at to tidligere eller nuværende ansatte i RNTech SAS France er forfatterne af denne manuskript ændrer ikke tilslutning til alle de PLoS ONE politikker om datadeling og materialer som beskrevet i online guide for forfattere.
Introduktion
Dødeligheden af mange kræftformer ikke har ændret sig dramatisk i sidste 20 år [1]. Tidlig påvisning blev vist i høj grad at forbedre effektiviteten af kræftbehandling, men påvisning er ofte kun mulig efter fremkomsten af de første kliniske symptomer, som i visse kræftformer opstår for sent for vellykket indgreb. Dette skyldes i høj grad mangel af specifikke og følsomme tests, der tillader tidlig screening og overvågning af kræft stater. Derfor er opdagelsen af hidtil ukendte tumor biomarkører betragtes i stigende grad kritisk at forbedre kræftbehandling. I det seneste årti har mange undersøgelser fokuseret på biomarkør opdagelse. Et af de mest lovende kilder til biomarkør opdagelse er den menneskelige blod, især serum og plasma, som kan afspejle mange begivenheder i kroppen, i realtid. Trods store anstrengelser, kun et meget lille antal plasmaproteiner har vist sig at have diagnostisk værdi [2] - [5]. Ofte har disse biomarkører ikke stå alene og er ledsaget af andre tests til overvågning og diagnosticering. De fleste af dem er ikke specifikke og følsomme nok til bredformat diagnose [6], [7].
En mulig kilde til nye kræft biomarkører er peptidindhold. Rationalet bag fokus på serum-peptider er baseret på dokumentation for, at kræft dannelse og udvikling indebærer ændringer i proteiner 'og peptider' stofskifte, og på den øgede tilgængelighed af metodik til screening af hele peptidindhold. Med hensyn til udvikling af kræft, kan der forekomme ændringer i vifte af intra- og ekstra-cellulære peptider repræsenteret i blodet peptidindhold, som kan være specifikke for kræft scenen, og har dermed en diagnostisk potentiale [2], [4], [ ,,,0],5]. Med hensyn til påvisning teknologi, seneste fremskridt inden for MS teknologi muliggøre detektion af hundredvis af peptider fra et par mikroliter serum [8], [9]. Faktisk rapporterede tidligere blod peptidindhold undersøgelser en række signatur peptider i serum, der var skelnes sundt fra kræftpatienter (revideret i [5]). Dette blev vist for prostata, blære, bryst og skjoldbruskkirtel kræft ved Villanueva et al I dette arbejde, vi fokuserede på at opdage en række signatur peptider, der kunne have diagnostisk værdi for mavekræft. For at opnå dette, brugte vi tre forskellige serum kilder involverer maven kræftpatienter på forskellige stadier. En streng protokol for serum indsamling og behandling blev påført [18], under anvendelse af en sammenhængende fremgangsmåde peptid ekstraktion og MALDI-TOF aflæsninger, med en modificeret analyse rørledning. Sammen den forbedrede rørledning tilladt til identifikation af et peptid mønster, som skelner mellem kræft og kontrolprøver. Disse resultater blev bekræftet på den oprindelige og nye sera for tre identificerede funktioner fra mønsteret, apoC-I (to funktioner) og apoC-III, ved hjælp af immuno-assays. Vi derefter ansat serumniveauer af apoC-I og apoC-III kombineret med CRP og CA19-9 markører til at skelne mave adenocarcinom patienter fra kræft-fri kontrol. Serum høst og håndtering Sera blev opnået fra to kommercielle kilder. 79 serumprøver fra præ-operation mave kræftpatienter og 33 serumprøver fra kræft-fri matchede kontroller (herunder 10 gastritis patienter) blev indsamlet ved RNTech (Paris, Frankrig) i Rumænien. Sera formular cancer og ikke-cancerpatienter blev taget efter faste natten over på følgende måde: 5 ml blod blev trukket ind i en VACUETTE serum rør (CatLj.005, Greiner Bio One, Kremsmuenster, Østrig) og venstre til at størkne i ca. 30 minutter, hvorefter røret blev centrifugeret ved 3000 rpm på en Hettich EBA 20S centrifuge (Hettich Ag, Tuttlingen, Tyskland) i 5 minutter ved stuetemperatur. Det separerede serum blev opdelt i alikvoter i 1 ml portioner i sterile kryogene rør (Nalgene, Rochester, NY, USA) og straks nedfrosset ved (-70) ° C. 22 pre-operation mavekræft sera og 21 kontroller blev indsamlet af Asterand i USA (Detroit, MI, USA) på følgende måde: 10 ml blod blev trukket ind i en BD vacutainer SST plus plastrør (kat #BEC 367.985, BD , San Jose, CA, USA). Røret blev blandet ved at vende det 5 gange og efterladt til at størkne i ca. 30 minutter i en lodret position. Dette trin blev efterfulgt af en centrifugering af 1.100-1.300 g i 10 minutter ved stuetemperatur. Det separerede serum blev opdelt i alikvoter i 1 ml portioner i sterile kryogene rør (Nalgene) rør og straks nedfrosset ved (-70) ° C. For Asterand kilde, fastede data ikke indsamles på nogen af blodet trækker i deres bank. Sera prøver fra begge selskaber blev transporteret på tøris og opbevares ved (-70) ° C straks ved ankomsten. Sera prøver blev optøet på is i cirka en time og en halv, 50 pi blev opdelt i portioner i lo-binder rør (Eppendorf, Hamborg, Tyskland), og straks igen frosset ved (-70) ° C. Alle prøvealiquoter blev opbevaret ved (-70) ° C indtil bearbejdning. En tredje kilde til sera blev opnået i vores laboratorium fra 12 kræft-fri israelske kontroller. Blod blev udtaget med røret mærke anvendes af RNTech (CatLj.005, Greiner Bio One) og serum håndtering ved proceduren ifølge RNTech. Opnået i vores laboratorium sera blev taget fra ikke-fastende individer. Både RNTech og Asterand virksomheder har etableret og udført deres aktiviteter efter lovgivningsmæssige og etiske standarder, implementering lokalt, nationalt, europæisk, amerikansk og international (FN) regler og anbefalinger, især når der gælder for biologisk materiale indsamling og behandling og resultat forskning udnyttelse. Dette omfatter både skriftlige samtykke for hver patient, der bidrager til den biologiske og databank, og skriftlig tilladelse undersøgelse fra den etiske komité for hvert klinisk institut bidrager prøver til selskabernes banker. Hvert serum prøve blev behandlet i to til tre gentagelser (fra identiske portioner og på separate tilfældige datoer). Peptider blev ekstraheret på perler overtrukket med C8, vasket, elueret, blandet med CHCA matrix, og deponeres på MALDI målplade. Sera blev forarbejdet i replikater og aflejres på MALDI plade i dubletter. For detaljeret beskrivelse henvises File S1. Databehandling blev udført i to trin. I det første trin blev en intensitet matrix udført fra de rå ASCII filer af MALDI-TOF aflæsninger fra alle sera eksempelkilderne hjælp re-sampling, tilpasse, og m /z toppe detektion som beskrevet i Villanueva et al (1) en gengivelse summation og har filter trin blev sat til at overveje nul værdier som særlige tilfælde. Vores oprindelige matrix indeholdt en betydelig mængde nul værdier for forskellige funktioner i forskellige prøver. På grund af generel begrænsning af MALDI-teknologi, kan en betydelig del af disse nul værdier repræsenterer manglende værdier snarere end sande nul intensiteter. For delvist overvinde denne begrænsning, vi læser hver prøve i replikater, og beregnet den gennemsnitlige intensitet, ignorerer nul intensitet aflæsninger. Efter denne replikere summation, det resulterede matrix indeholdt stadig betydelig mængde nul værdier. SVM-baserede modeller kan klassificere i henhold til nul-værdier repræsenterer manglende værdier og ikke sande nul intensitet. Derfor har vi bortfiltreret funktioner, der stadig havde nulværdier i mindst én af prøverne. Ingen af disse fjernede funktioner havde klar præference for nul værdier til en specifik klinisk gruppeopgave. Den resulterende sub-matrix blev anvendt i en maskine læring klassificering. (2) En ny tilgang til indslag valg parametreringen blev udviklet. Definitionerne for SVM-baseret analyse var oprindeligt som følger: RNTech mave vs. RNTech kontrol, Asterand mave vs. Asterand kontrol. Mann-Whitney p-værdi blev beregnet for hver top, ifølge kliniske grupperne defineret for analysen. Vi derefter brugt Mann-Whitney p-værdier og topintensiteter som cutoffs for at vælge en delmængde af funktioner (toppe) til brug i machine learning eksperimenter. En intensitet cutoff ikke bortfiltrere prøver, hvori mindst en gennemsnitlig aflæsning havde intensitet over cutoff for den testede top. Filter værdier blev optimeret til bedste ydelse i SVM-baserede klassificører (produceret af LIBSVM, lineær kerne) i henhold til ti gange krydsvalidering af en to-trins-protokol. Det første skridt definerede søgning intervaller og intervaller for begge filtre og iteration frem for alle kombinationer. Derefter vælges det andet trin kombinationen af værdier, som gav den bedste ydeevne og mindste antal funktioner. (3) En normalisering skridt blev tilsat for at styre på tværs af prøve- og cross-eksperiment fordomme. For sera kilder 'sammenligning og udvælgelse af funktioner, der viser lignende tendenser i begge kilder, var cross-source normalisering af intensiteter udføres ved hjælp af R-funktionen "fraktil" til at definere 9 tærskler X 1 Yderligere bioinformatiske metoder findes i File S1. Immuno-baserede kommercielle og kliniske analyser for forskellige apolipoproteiner Salg ApoC-III og apoB-100-niveauer blev målt ved Immunoturbidometry på et Olympus 400 autoanalyseapparat, ved hjælp af K-assaykit (cat # KAI-006 og 6142, Kamiya Biomedical, Seattle, WA, USA) som tidligere beskrevet [22]. I hus ELISA for apoC-III er beskrevet i File S1. ApoC-I-niveauer blev testet under anvendelse af et AssayMax Humant Apolipoprotein C-I-ELISA-kit (Assaypro, St. Charles, MO, USA) ifølge producentens anvisninger. Oprenset humant apoC-I standarder blev inkluderet i sættet. Anvendelse af MS-metode til at identificere serum peptider signatur for mavekræft Tidligere undersøgelser viste, at godt -Designet og omhyggeligt kontrollerede sera peptidomics kan adskille specifikke kræftpatienter-bærende og ikke-kræft kontroller baseret på karakteristiske mønstre af signatur peptider i serum [10], [11]. Vi undersøgte, om disse resultater kan reproduceres til mavekræft og om en sådan adskillelse er tilstrækkelig til analyse af sera fra forskellige kilder. Vi analyserede først serum peptid profiler af 62 patienter med mavekræft på forskellige stadier, samt 41 kontrolsera fra raske frivillige. Disse sera blev opnået fra to kilder: (i) RNTech, et selskab, der har indsamlet sera i Bukarest, Rumænien og (ii) Asterand, et selskab, der har indsamlet sera i USA. For hver kilde, blev sera opsamlet ved anvendelse af en enkelt standard klinisk protokol. Protokollerne var sammenlignelige, f.eks typen af røret, koagulationstiden og den indledende frysning af sera (se fremgangsmåder), men blod tilbagetrækning rør var forskellige. Aldersfordeling, køn og kliniske karakteristika af de 103 personer, der indgår i denne undersøgelse er angivet i tabel 1 og mere detaljeret i File S1. Et resumé af kliniske stadier af mavecancer-afledte sera for begge kilder er givet i tabel 1. Prøve håndtering efter den indledende indsamling var ensartet, involverer 2 fryse-tø-cykler til at opnå initial lagring og efterfølgende udportionering for peptid ekstraktion og MS-analyse. Alle 103 serumprøver blev behandlet manuelt, men identisk anvender et-trins omvendt fase-ekstraktion. Sera prøver og prøve replikater blev behandlet og læse tilfældigt på forskellige datoer at undgå forberedelse dato-associeret bias. Alt forberedelse og deposition sera blev udført af den samme person. Ligeledes blev alle MALDI aflæsninger udføres af den samme tekniker. Den MALDI-TOF instrumentets følsomhed blev overvåget rutinemæssigt og konstant kalibreret under alle aflæsninger. i alt 637 masse toppe (funktioner) blev identificeret i de 103 undersøgte prøver. Resultaterne af MALDI blev konverteret til en matrix med signalintensiteter af 637 mass toppe (funktioner) for hver af de undersøgte serumprøver med replikater for hver prøve (se metoder, bioinformatik). Mens opsyn hierarkisk klyngedannelse hjælp af alle funktioner ikke adskille kræft og ikke-kræft prøver, PCA analyse af alle funktioner for hver sera kilde differentieret mellem kræft og ikke-kræft prøver (figur S1-S3). Dette antydede, at funktionen filtrering og udvælgelse er vigtigt, før ansætte machine learning-baserede klassificering. Derfor er vi (i) anvendt en funktion filtrering og udvælgelse skridt, og (ii) ansat Mann-Whitney p-værdier og topintensiteter som cutoffs for at vælge en delmængde af funktioner (toppe) til brug i machine learning eksperimenter. (Se metoder, bioinformatik). Vi analyserede derefter inden for hver kilde (RNTech og Asterand) hvorvidt sera fra patienter og kontrolpersoner kunne holdes adskilt. Vi fik gode resultater for hver af de single-source klassificører; SVM-baserede klassificører for RNTech og Asterand havde 90,0% og 93,0% af forventet nøjagtigheder, henholdsvis ifølge ti gange cross validering af træningssættet (tabel 2A). Tilfældig blander af gruppens medlemmer resulterede i meget højere p-værdier (for eksempel 0,8) og lav forudsagt nøjagtighed i trænede modeller pr hver sera kilde. Dette indikerede betydningen af kliniske tilstande for klassificering i to klinisk definerede grupper inden for hvert sera kilde. Men de single-source klassificører ikke klarer sig godt på den anden kildes prøver at forudsige korrekt klinisk status kun i 35/60 prøver (Asterand på RNTech) og 25/43 (RNTech på Asterand) (tabel 2A). Derfor kilde bias peptidindhold har en signifikant effekt på nøjagtigheden af forudsigelsen. Den manglende evne af modeller, uddannet på én kilde i tilstrækkelig grad forudsige kliniske tilstande fra aflæsninger fra den anden kilde (tabel 2A) er bedre fremlagt, når kontrol udvælger de kildespecifikke klassifikatorer (tabel 3) funktioner. Nogle af de funktioner, som fungerede godt på én kilde viste en modsat tendens på den anden kilde. Andre var vigtigt for klassificering i en kilde, men havde ringe eller ingen effekt i den anden. Disse observationer førte os til en sammenlignende analyse af data fra begge kilder. Vi producerede kassediagrammer for alle topintensiteterne, ifølge kliniske grupper. Disse plots viste, at når man sammenligner intensiteter kontrol- og cancer for hver funktion i en kilde, kunne den observerede tendens variere mellem de to kilder (fx m /z 1520, figur 1A). Selv når tendens var vedholdende i begge kilder, kunne intensitetsværdierne være forskellige (for eksempel m /z 6431; RNTech højere end Asterand, figur 1 B). For at skabe en forudsigelse model, vi havde brug for at (i) discard kilde-specifikke fænomener, og (ii) tilføjer en normalisering skridt, som vil reducere effekten af forskellige intensitet niveauer, hvor tendensen blev opretholdt. brug af den blandede datasæt med en Mann-Whitney p-værdi cutoff for funktionen udvælgelse kunne skille kildespecifikke fænomener. Peaks, som viste forskellige tendenser i forskellige kilder ikke vil være betydelige i blandet sæt til klinisk gruppebaseret separation; Funktionen 1520 manifesterer modsatte tendens mellem kilder, blev valgt af hver enkelt kilde klassificeringen (figur 1A, tabel 3). Derfor den bidrog til den manglende vellykket udførelse af hver enkelt kilde klassificeringen på den anden kilde (tabel 2A). Som forventet blev denne funktion ikke valgt som helst model baseret på blandet sæt. Vi skabte en blandet datasæt, mens tilfældigt fjerne 21 mavekræft prøver fra den blandede træning sæt, og brugte disse 21 fjernet prøver til validering. Derudover har vi brugt de 12 kræft-fri kontrolprøver indsamlet i vores laboratorium, som en uafhængig kontrol validering sæt. Modellen blev valgt i overensstemmelse med en maksimal forudsagt nøjagtighed ifølge en ti-fold validering af feltet som før. Den bedste scoring model for blandet sæt var hjælp 9 funktioner (Mann-Whitney p-værdi filter af 0,044) og havde en forudsagt nøjagtighed på 84,1% ifølge ti gange krydsvalidering af træningssættet. Vigtigt er det, det forudsiges nøjagtigt 10/12 israelske kontrol. Men denne sorterer forudsagde utilstrækkeligt (13 af 21) de 21 fjernet blandet mavekræft prøver anvendes til validering. Derfor, for at reducere effekten af kilderelaterede forskelle i intensitet niveauer, filteret præstation i funktionen valg var forbedret ved at indføre en fraktil normalisering trin. Denne normalisering blev udført ifølge kontroller af hver sera kilde uafhængigt af de andre kilder (se metoder, bioinformatik). For funktioner, såsom m /z 6431 med en vedvarende tendens i begge kilder, dette trin korrigeret intensiteten bias (figur 1D). Faktisk blev 6431 funktion ikke er valgt for det ikke-normaliserede mix-baserede klassificeringen. Imidlertid blev det valgt til det normaliserede mix-baserede klassifikator (tabel 3). Men for funktioner som m /z 1520 med modsatrettede tendenser i begge kilder, dette trin kunne ikke ændre den tendens, som forventet (figur 1C). Vi testede den fraktil normalisering effekt ved at anvende den, før gennemsnittet og funktion valg. For bedre at vurdere forudsigelse nøjagtighed vi beskæftigede Matthews Correlation Coefficient (MCC) foranstaltning. MCC bruges i machine learning som et mål for kvaliteten af binære (to klasse) klassifikationer og returnerer en værdi mellem -1 og +1. En koefficient på 1 repræsenterer en perfekt forudsigelse, 0 en gennemsnitlig tilfældig forudsigelse og -1 en invers forudsigelse. MCC er generelt betragtes som en afbalanceret foranstaltning, der kan anvendes, selv om klasserne er af forskellig størrelse. Vi således beregnede MCC til eksperimenter forskellige klassifikationssystemer for at vise den virkning, at normalisering havde på klassificering. Resultater er vist i tabel 2. Bemærk, at uden normalisering, MCC var relativt høj for træningssættet, men viste middelmådige resultater på validering sæt (tabel 2). Normaliseringen skridt gav lignende høje MCC værdier for uddannelse og validering sæt (tabel 2). Normaliseringen skridt til at styre på tværs af kilde partiskhed ikke annullere behovet for machine learning-baserede klassificeringen til at definere en diskriminerende mønster; PCA af de to kilder-blandede normaliserede datasæt resulterede igen i dårlig adskillelse mellem mavekræft og kontrolprøver (Figur S4). sorterer resulterede fra den blandede datasæt, efter fraktil normalisering trin, ansat 9 funktioner (tabel 2). Tre af de 9 funktioner involveret apolipoproteiner: apoC-III (feature 9443) og apoC-I (funktioner 6431 og 6629, tabel 3). For yderligere at verificere MALDI-baserede resultater, vi først udviklet en ELISA-test til kvalitativ påvisning af apoC-III i serum (se metoder) og testet alle serumprøver fra Asterand og RNTech. Resultater af ELISA fulgte udviklingen i de MALDI resultater (figur 2A, B); Intensiteten af apoC-III var signifikant højere i kontrolgrupper sammenlignet med cancer grupper i begge sera kilder. Vi yderligere analyseret sammenhængen mellem apoC-III ELISA og 9443 MALDI resultater pr hver prøve; ELISA og MALDI Resultaterne viste signifikant sammenhæng (p < 0,0001, Kendall s ran korrelation tau). Vi sendte derefter sera portioner fra næsten alle prøver (samme fryse state) til en ekstern klinisk laboratorium for immunoturbidity-baserede kvantitativ analyse for apoC-III [22]. Resultaterne blev opnået i mg /dl (Figur 2C) og som ovenfor, mængde apoC-III var signifikant højere i kontrolgrupper af begge sera kilder. For at verificere de apoC-I MALDI resultater vi ansat en kommerciel kvantitativ ELISA kit, der indeholder apoC-i-standarder og anerkender både 6431 og 6629 varianter af apoC-i. Resultater blev opnået i pg /ml (figur 3B) og fulgte mønsteret observeret for MALDI resultater (figur 1D og 3A); Intensiteten af apoC-I var signifikant højere i kontrolgrupper sammenlignet med cancer grupper i begge sera kilder. For at vurdere specificiteten af apoC-I og reduktion apoC-III i sera fra mavekræft-bærende patienter, vi analyseret apoB-100 niveauer. Prøverne analyseres for apoC-III i det eksterne kliniske laboratorium blev analyseret parallelt for apoB-100 niveauer ved hjælp immunoturbidity baseret kvantitativt assay. Resultater blev opnået i mg /dl (figur 3C) og udviste ingen signifikant tendens mellem kontrol- og mavekræft-bærende grupper. Derfor kunne vi gøre brug af apoB-100 resultater som en normaliseringsfaktor for bioinformatik analyse af de kvantitative apoC-I og apoC-III resultater (figurerne 3C, 3B, 2C). Vi analyserede klinisk apoC-i, apoC-III og apoB-100 for yderligere prøver fra patienter mavekræft og kræft-fri kontroller (RNTech kilde, samme fryse-tilstand, herunder 10 gastritis patienter i cancer-fri kontrol, note Tabel 1 for den samlede prøvenumre). Vi analyserede også klinisk CA19-9 og CRP niveauer for alle prøver (samme fryse-state). Vi derefter anvendes Clementine 10.0 software på de RNTech prøver for at vurdere, om regler fastsat på grundlag af apoB-100-normaliseret CI og C-III, CA19-9 og CRP serumniveauer kan anvendes til at klassificere mellem sera fra kontrol- og mavekræft grupper af RNTech kilde som en uddannelse kilde. Kombinationen af alle 4 parametre gav bedre forudsigelse nøjagtighed sammenlignet med kombination af mindre end 4 parametre (figur 4 og data ikke vist). Forudsigelse nøjagtighed træningssættet var 88,4%. Vi anvendte de RNTech-opnåede regler for Asterand kilden og forudsigelse nøjagtighed var 74,4% (figur 4). For både træning og validering følsomheden var fremragende (87/90 kombineret) men specificiteten var mindre præcis (37/52 kombineret). I de seneste år, en hel del rapporter beskriver MS-identificerede serum biomarkører /underskrifter for kræft stater blev bevist forkert [5], [18]. Forskellige kilder til skævhed blev beskrevet herunder stikprøveudvælgelsen, håndtering, forarbejdning, læsning og analyse [18], [20], [21]. Efter fjernelse til bias-medvirkende faktorer, blev det vist, at SELDI-TOF MS hele serum proteomisk profilering med IMAC overflade ikke detektere prostatacancer [23]. Derfor forfatterne foreslog, at det er usandsynligt, at en massespektrometri tilgang med ubehandlet serum ville skelne mellem mænd med og uden prostatacancer [24]. På den anden side, andre nylige MALDI-TOF-baserede studier, der undgås skævhed-medvirkende faktorer og ansat en et-trins sera teknik identificeret diskriminere biomarkør signaturer til forskellige kræftformer, herunder prostatakræft [11]. I denne studie vi vedtog et skridt sera behandling tilgang til identifikation af et peptidindhold-baserede signatur til at differentiere sera stammer fra maven adenocarcinom patienter. Vi gjorde en rimelig indsats for at undgå tidligere rapporteret skævhed medvirkende faktorer [18]. Vi analyserede sera fra to biorepositories. Vi observerede, at selv når sera håndtering, forarbejdning, MALDI læsning og analyse er de samme, er peptidindhold analyse forspændt af biorepository. Ud over de socio-geografiske forskelle (Rumænien og USA som kilde til prøverne i RNTech og Asterand henholdsvis), kilden-relaterede skævhed kunne være på grund af brand i blodet tilbagetrækning rør, der anvendes i de forskellige biorepositories. Vi brugte derefter en blandet prøvesæt fra to sera kilder til funktionen udvælgelse og tilføjet en cross-kilde normalisering trin for at kompensere for kilde bias. Vi fandt, at (i) brugen af den blandede datasæt med en Mann-Whitney p-værdi cutoff for funktionen udvælgelse kunne skille kildespecifikke funktioner, og (ii) en fraktil normalisering trin hjælper til at vælge (for machine learning) delvist overensstemmende funktioner , hvor tendenserne er overensstemmende mellem kilderne, men intensitetsniveauer er forskellige mellem kilderne. Behovet for normalisering, når det drejer sig prøver fra forskellige kilder, blev allerede vist for microarray-baserede high throughput teknologi [25]. Det er velkendt, at variationer i eksperimentelle procedurer og ukontrollerede forhold (f.eks socio-geografiske oprindelse af prøver) kan føre til systemiske måling bias. Efter de ændringer, vi etableret et cross-source serum peptid signatur til at skelne mave kræftpatienter fra kontroller uden cancer. Tre af peptiderne svarede til apoC-I og apoC-III. Vi validerede vores MALDI-baserede resultater med uafhængige analysemetoder, der er baseret på immunoassays [26]. Peptidet signatur inkluderet apoC-III og apoC-I-afledte funktioner. Resultaterne fra uafhængige kvantificering af deres serumniveauer fulgt tendensen identificeret af MS tilgang. Vores undersøgelse er den første til at rapportere, at serumniveauer af apoC-I og apoC-III kan anvendes som potentielle biomarkører for mave kræft. Det er rigtigt, at de seneste rapporter har indikeret, at apolipoproteiner 'niveauer i blodet kunne være potentielle biomarkører for forskellige kræftformer. ApoC-I blev identificeret som et potentielt serum biomarkør for tarmkræft, hormon-refraktær prostatakræft og lever fibrose [27] - [29]. Andre rapporter viste, at apoC-III også kunne være en potentiel biomarkør i bugspytkirtelkræft og brystkræft [30], [31]. Men alle disse rapporter beskæftigede MALDI-baserede screening og ikke kontrollere deres resultater med immuno-baserede eller andre analyser. Heller ikke de studerer sera fra en anden kilde som en validering gruppe. Vores resultater bør yderligere brugt og valideret som beskrevet [32], [33]. Men den kliniske validering af apoC-I og apoC-III resultater får os til yderligere at udforske et diagnostisk assay baseret på serum biomarkører, der kunne analyseres i klinikken uden behov for MS-teknologi. Reglerne udnytte apoB-100-normaliseret C-I og C-III, CA19-9 og CRP kvantitative serumniveauer genereret for RNTech kilden og valideret på den uafhængige Asterand kilde havde forudsigelse nøjagtighed på 88,4% og 74,4%, hhv. Derfor er brugen af kliniske disse 4 funktioner delvist overvinder kilden bias.
[10], [11]. De rapporterede 61 signatur peptider, der kunne skelne raske personer fra 3 forskellige typer kræftpatienter. Mens alle disse peptider og /eller deres fragmenter normalt findes i serum, er forskelle i mængde mellem raske og syge individer observeret. Men selv om disse resultater viser det potentiale, peptidindhold profiler har for kræft diagnose, er det stadig, der skal vises, at denne tilgang kan udvides til at opdage biomarkører egnet til tidlig diagnose og konsekvent overvågning. Først blev evnen af disse sera peptid biomarkører til at skelne patienter fra kontroller meste påvist for patienter med meget avancerede eller metastatiske tumorer. Desuden har robustheden af disse biomarkører blevet udfordret; ukontrollerede variabler, hovedsagelig tilskrives forskelle i prøvehåndtering, behandlingsprotokoller og dataanalyse, har vist sig at dramatisk ændre resultaterne af disse assays [11] - [19]. Ved at sætte større fokus på erhvervelse prøve, håndtering, forarbejdning, MS signalbehandling og statistiske analyser kan opnås mere robuste og reproducerbare resultater [18], [20], [21].
Materialer og metoder
Serum prøve behandling og forberedelse til MS MALDI læsning
Data analyse af MALDI resultater
[21]. I det andet trin blev maskinlæring anvendes til at definere en diskriminerende mønster, der kan anvendes til at klassificere patienter. Til dette formål fremgangsmåden beskrevet i Villanueva et al
[21] blev modificeret som beskrevet nedenfor. Den modificerede rørledning udelukkende afhænger open source software og yderligere detaljer er beskrevet i afsnittet bioinformatik i File S1.
. 9
der opdele skalerede værdier i kontrolgruppen klassen i 10 fraktiler.
Resultater
Analyse af MS-baserede sera peptidindhold afslørede en 9-peptid signatur, der skelner mave adenocarcinom patienter fra kræft gratis kontroller
Immuno-baserede validering for funktioner, der repræsenterer apoC-I og apoC-III
Diskussion
 Mor-til-baby SARS-CoV-2-transmission under graviditet mulig, men sjælden,
Mor-til-baby SARS-CoV-2-transmission under graviditet mulig, men sjælden,
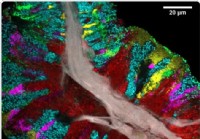 Detaljeret kort over menneskelig tunge mikrobiom
Detaljeret kort over menneskelig tunge mikrobiom
 Proteinsendinger fra humant mikrobiom kaster lys over menneskers sundhed
Proteinsendinger fra humant mikrobiom kaster lys over menneskers sundhed
 Metformin kan hjælpe utæt tarm
Metformin kan hjælpe utæt tarm
 Tarm og orale mikrobiomer forudsiger sværhedsgraden af COVID-19
Tarm og orale mikrobiomer forudsiger sværhedsgraden af COVID-19
 Kunne mikroalger afledte antivirale forbindelser bekæmpe SARS-CoV-2 og andre vira?
Kunne mikroalger afledte antivirale forbindelser bekæmpe SARS-CoV-2 og andre vira?
 Det er sikkert at fodre råfoder til kæledyr,
finder en ny undersøgelse En stor multinationel undersøgelse viser, at dyreejere ikke tror, at fodring af rå mad øger risikoen for infektion for husstandens medlemmer. Rå mad omfatter alt ubehandlet
Det er sikkert at fodre råfoder til kæledyr,
finder en ny undersøgelse En stor multinationel undersøgelse viser, at dyreejere ikke tror, at fodring af rå mad øger risikoen for infektion for husstandens medlemmer. Rå mad omfatter alt ubehandlet
 Alvorlige COVID-19-komplikationer forbundet med nedbrydning af tarmbarrieren
Et stort fokus for forskning i den nuværende coronavirus-sygdom 2019 (COVID-19) pandemi har været behovet for at forstå de mekanismer, der virker, der forårsager denne potentielt dødelige sygdoms fors
Alvorlige COVID-19-komplikationer forbundet med nedbrydning af tarmbarrieren
Et stort fokus for forskning i den nuværende coronavirus-sygdom 2019 (COVID-19) pandemi har været behovet for at forstå de mekanismer, der virker, der forårsager denne potentielt dødelige sygdoms fors
 Scientific Symposium på LABVOLUTION fokuserer på centrale spørgsmål inden for biovidenskab
Det videnskabelige symposium på LABVOLUTION vil fokusere på centrale spørgsmål inden for biovidenskaben. Derfor, der forventes et højt niveau af besøgende. Det videnskabelige symposium få
Scientific Symposium på LABVOLUTION fokuserer på centrale spørgsmål inden for biovidenskab
Det videnskabelige symposium på LABVOLUTION vil fokusere på centrale spørgsmål inden for biovidenskaben. Derfor, der forventes et højt niveau af besøgende. Det videnskabelige symposium få